The overall objective of the CASH team is to design and develop ways to improve the quality of software. We work both on tools that help programmers write better programs, and compilers that turn these programs into efficient executables. The scope of targeted applications is wide, from specialized HPC applications on supercomputers to general purpose computing, from massively parallel applications to sequential code, from functional languages to imperative code, etc. Our main focus is software, but we also consider hardware, both as an execution platform for software, and as a research topic (hardware generation and hardware circuit analysis). What links all our activities is that our object of study is computer programs.
By improving the quality, we mean both the safety of programs and the efficiency of their execution. We notably provide programmers with better programming language constructs to express their intent: constructions that give them guarantees by-construction such as memory-safety, determinism, etc. When guarantees can’t be obtained by construction, we also develop static analyses to detect bugs or to prove preconditions needed to apply program transformations. We use such guarantees to develop new optimizations to generate efficient code. All these contributions find their foundation and justification in the semantics of programs. Additionally, we provide simulators to execute programs that require a specific execution platform.
When it comes to high level programming constructs for parallelism, we develop a specific expertise in asynchronous computations and ruling out race-conditions in concurrent programs. In this realm, we propose new paradigms, but also contribute to the semantics of such programs. For instance, we design ways to specify the semantics using monadic interpreters, and use them to study the correctness of compilers.
We ensure safety guarantees both through type-systems and analyses, in vastly different contexts: from the verification of electrical circuits to the design of a new module systems for OCaml. As is recurrent in our work, we pragmatically adapt the approach to the practical application at hand.
We design code transformation for the efficient execution of programs, in particular targeting HPC. Our contributions in this realm extend the polyhedral model to make it applicable to a wider range of programs, and to bring its potential for optimisation to new kind of applications (parametric tiling, sparse structures, …). We also design optimisations for structured data such as trees, or more generally algebraic data types.
The research directions of the team are:
- Programming Language Design. The team works on high-level programming languages constructs that can both help programmers write programs without bugs and help compilers generate more efficient code. We are particularly interested in parallel programs, but also provide tools for sequential code.
- Semantics and Proofs. Interactive provers like Rocq allow writting machine-checked mathematical proofs, and also in certified computer programs. We work both on tools for writting better proofs or formalization of semantics, and on the application of these tools in particular for certified compilation.
- Program Analysis and Verification. We design expressive and scalable static analyses. The analyses we design both apply to performance optimization (by computing invariants used by optimizing compilers) and safety (by automatically finding bugs or proving correctness properties on programs or electrical circuits).
- Optimizations and Program Transformations. We propose several automatic program transformations to improve their performance. On framework of particular interest to the team is the polyhedral model able to perform very agressive optimizations for regular imperative programs.
Contact
For more information, please contact the team leaders: Matthieu Moy and Ludovic Henrio via the email alias resp.cash.lip at ens-lyon.fr.
More information:
Slides presenting the CASH team
Document presenting the CASH team at its creation in 2018
Short video presenting the team
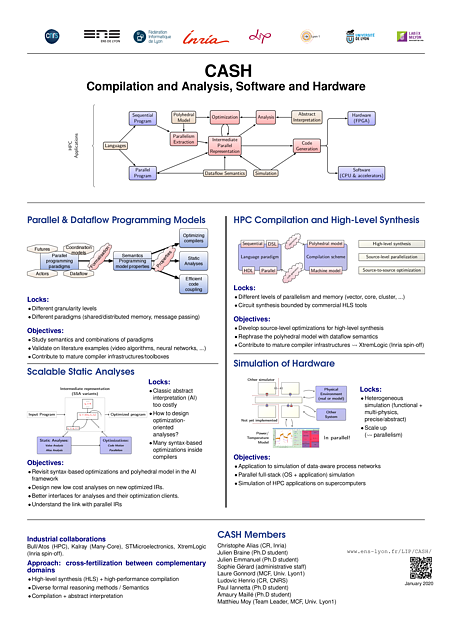
CASH poster: